능동추론 vs 기존 이론들
| 이 글은 Thomas Parr, Giovanni Pezzulo의 교재 “Active Inference”의 마지막 장을 읽고 정리한 글임을 밝힙니다. |

능동 추론 vs 기존 이론
(1)철학; 예측 이론
전통적인 뇌와 인지 이론은 자극이 반응으로 변환되는 피드포워드 모델을 강조하지만(그 사이의 모든 것들은 “인지적Cognitive”이라고 불린다), 능동 추론(Active Inference)은 예측과 목표 지향적 측면을 강조한다. 능동 추론 생명체는 생성 모델을 기반으로 예측을 생성하고, 이를 통해 가설을 검증하고 모델을 수정하며, 데이터를 능동적으로 수집한다. 이 과정에서 인식적(Epistemic) 요구(정보 탐색)와 실용적(Pragmatic) 요구(보상 확보)를 충족시킨다.

Predictive Processing 예측 처리(Predictive Processing, PP)는 뇌와 인지를 예측 중심으로 보는 철학적 틀로, 예측을 뇌와 인지의 중심으로 간주하며 “예측적 뇌” 또는 “예측적 마음” 개념을 사용한다. PP 이론은 능동적 추론(Active Inference)과 관련이 깊으며, 생성 모델, 예측 부호화(Predictive Coding), 자유 에너지, 정밀도 조절, 마르코프 블랭킷 등 일부 개념을 공유하지만, PP는 더 넓은 의미로 사용된다. PP 이론은 지각, 행동, 학습, 정신병리학 등 다양한 인지 영역과 간단한 생물학적 유기체에서 사회적, 문화적 구조에 이르기까지 통합할 수 있는 잠재력으로 주목받고 있다. PP는 철학자들에게 익숙한 개념인 믿음Belief과 놀라움Surprise 등을 사용하지만, 이 개념들이 때로는 기술적 의미를 가질 수 있다. PP에 대한 관심이 커짐에 따라 철학자들 사이에서 이론적, 인식론적 해석에 대한 의견이 다양하며, 내재주의, 체화된 또는 행동 기반, 실행주의와 비표상적 관점 등으로 해석되고 있다.
(2)지각
능동추론은 지각을 생성 모델에 기반한 추론 과정으로 본다. 베이즈 규칙Bayes’ Rule은 관찰된 데이터를 바탕으로 환경의 숨겨진 상태에 대한 믿음을 계산하는 방식이다. 이는 헬름홀츠(1866)부터 시작된 오래된 개념으로, 심리학, 계산 신경과학, 기계 학습 등에서 재해석되어 왔다.
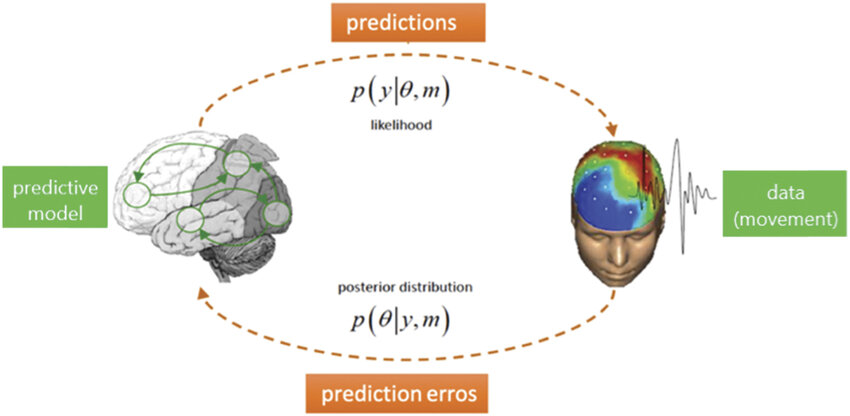
Bayesian Brain Hypothesis 베이즈 두뇌 가설(Bayesian Brain Hypothesis)은 이러한 아이디어를 현대적으로 표현한 것으로, 결정, 감각 처리, 학습 등 여러 영역에 적용된다. 능동 추론은 변동 자유 에너지를 최소화하는 원칙에 기반해 이러한 추론 아이디어에 대한 규범적 근거를 제공한다. 반면, 베이즈 두뇌 가설은 지각과 행동을 다른 명령에 따라 모델링한다. 능동 추론은 지각 추론의 전형적인 과정 모델인 예측 부호화(Predictive Coding)를 기반으로 지속적인 시간 속에서 행동 영역으로 확장된다. 이는 생성 모델의 원리를 통해 행동 동역학을 설명한다. 이와 달리, 베이즈 두뇌 가설은 뇌가 베이즈 최적(Bayes-Optimal) 감각운동(Sensorimotor)과 다종감각 통합(Multi-sensory Integration)을 수행한다는 계산 수준(Computational Level)의 제안, 샘플링 기반 의사결정과 같은 특정 베이즈 추론 근사치를 구현한다는 알고리즘 수준(Algorithmic Level)의 제안, 신경 집단이 확률적 계산을 수행하거나 확률 분포를 인코딩하는 방식에 대한 신경 수준(Neuronal Level)의 제안 등 여러 이론을 포함한다. 각 수준에서 다양한 경쟁 이론이 존재하며, 베이즈 계산은 여러 알고리즘 방식으로 실현될 수 있다. 반면, 능동 추론은 규범적 원칙과 과정 이론을 연결하는 더 통합된 관점을 제공한다. 규범적 수준에서 모든 과정은 변동 자유 에너지를 최소화한다고 가정한다. 이러한 추론을 위한 과정 이론은 자유 에너지의 기울기 하강(Gradient Descent)을 사용하며, 이는 명확한 신경생리학적 함의를 가진다. 예측 부호화는 자유 에너지 최소화 원칙에서 도출될 수 있으며, 연속 시간에서 예측 부호화 에이전트에 운동 반사를 부여함으로써 행동 영역으로 확장될 수 있다.
(3)행동 제어
능동 추론에서 행동 제어는 지각 처리와 유사하게 순방향 예측(Forward Prediction)에 의해 유도된다. 예를 들어, “내 손이 컵을 잡는다”는 고유수용감각 예측(Proprioceptive Prediction)이 잡는 동작을 유발한다. 행동 제어는 감각 입력에 덜 의존하고 뇌간 및 척수의 운동 반사(Motor Reflexes)와 연결되어 상대적으로 적은 상향식 입력을 받는다는 점을 제외하곤, 지각의 신경생물학 구조와 “동일”하다. 이는 행동이 목표 평형점(Equilibrium Point)을 설정하고 유지하는 평형점 가설(Equilibrium Point Hypothesis)과 연관된다. 행동을 시작하려면 사전 신념(Prior Belief)과 감각 입력의 신뢰도(Precision)를 적절히 조절해야 하며, 사전 신념이 더 정확할 때 잡는 행동이 발생한다. 이는 일시적인 감각 감쇠(Sensory Attenuation)를 통해 이루어지며, 감각 감쇠에 대한 실패는 행동 제어의 실패를 초래할 수 있다.

Ideomotor Theory 능동 추론에서는 행동이 운동 명령(Motor Command)이 아니라 고유수용적 예측(Proprioceptive Predictions)에 의해 발생한다. 이는 윌리엄 제임스의 관념운동 이론(Ideomotor Theory)과 관련이 있다. 이 이론은 행동과 효과 간의 양방향 연결성이 인지 구조의 핵심이라고 제안한다. 즉, 행동에서 효과로의 경우에는 그에 따른 감각 예측을 생성하고, 효과에서 행동으로의 경우에는 기대하는 효과에 따라 행동을 선택할 수 있게 한다. 능동 추론은 이러한 개념을 확장하여 신뢰도 제어(Precision Control)와 감각 감쇠(Sensory Attenuation)에 대한 추가적인 아이디어를 제공한다.
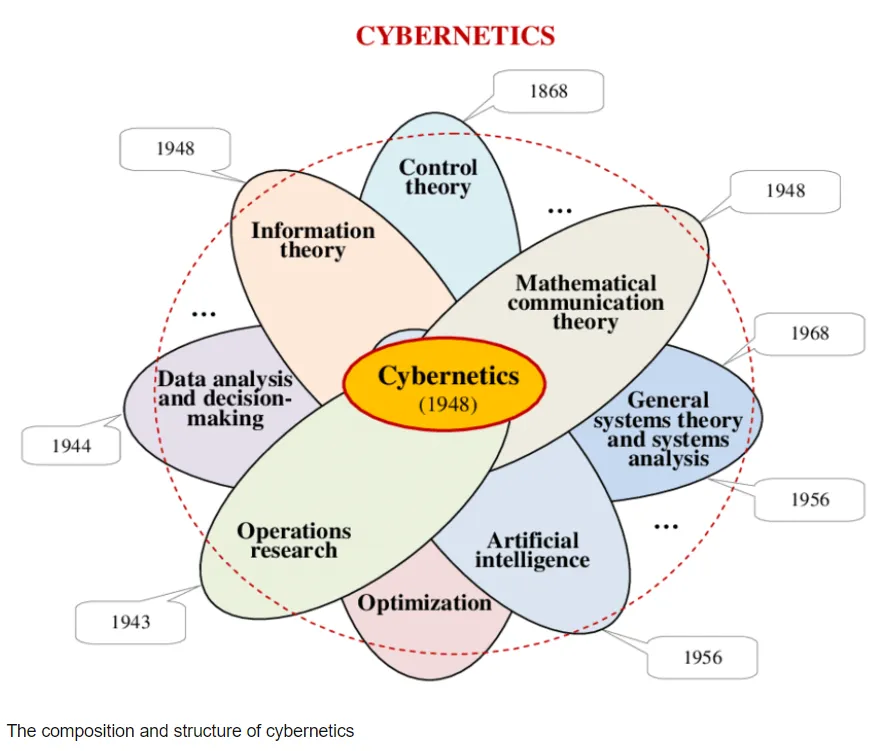
Cybernetics 능동 추론은 행동의 목표 지향성(Goal-Directedness)과 피드백 기반의 에이전트-환경 상호작용을 강조하며, TOTE 모델(Test-Operate-Test-Exit)과 유사하게 목표 상태(Preferred State)와 현재 상태 간의 차이에 따라 행동을 선택한다. 이는 단순한 자극-반응 관계(Stimulus-Response Relationship)를 가정하는 행동주의 이론(Behaviorist Theory)이나 강화 학습(Reinforcement Learning)과 구별된다. 오히려, 행동이 아니라 지각 상태를 제어하는 것을 핵심으로 하는 지각 제어 이론(Perceptual Control Theory)과도 유사하다. 능동 추론과 지각 제어 이론 모두 지각적 예측을 통해 행동을 제어한다는 공통점이 있다. 예를 들어, 운전 시 우리가 제어하는 것은 목표 속도일 뿐, 상황에 따라 가속이나 감속을 선택할 수도 있다. 이는 윌리엄 제임스의 “인간은 유연한 방식으로 안정적인 목표를 성취한다”는 통찰을 반영한다. 그러나, 능동 추론은 생성 모델을 통해 예측적(순방향) 제어(Predictive Control)를 포함하는 반면, 지각 제어 이론은 피드백 메커니즘(Feedback)이 충분하다고 본다. 또한, 두 이론 모두 상위 목표와 하위 목표의 계층적 연쇄(Hierarchical Cascade)를 통해 제어를 설명하지만, 능동 추론은 동기적 과정(Motivational Process)에 의한 신뢰도 가중치 조절(Precision Weight Modulation)에 따라 더 현저(Salient)하거나 급한 목표를 우선하는 기능을 포함한다.
Optimal Control Theory 최적 제어 이론(Optimal Control Theory)은 자극에 따른 반응을 결정하는 제어 정책(Control Policy)과 비용 함수(Cost Function)을 통해 운동 명령(Motor Command)을 선택한다. 이에 반해, 능동 추론은 예측적 제어(Predictive Control)를 사용하며, 운동 명령을 예측으로 간주하고, 생성 모델이 행동 제어의 핵심 역할을 한다. 최적 제어는 행동에 따른 결과를 예측하는 순방향 모델(Forward Model)과 그 예측을 바탕으로 비용 함수를 최적화하는 운동 명령을 탐색하는 역방향 모델(Inverse Model)을 필요로 하지만, 능동 추론은 단순한 반사(Reflex)에 기반한 순방향 모델로 충분하다. 능동 추론에서는 감각 예측 오류(Sensory Prediction Error)가 발생하면 행동을 통해 이를 해결하며, 복잡한 역방향 계산 대신 단순한 운동 반사를 고려한다. 또한, 능동 추론은 최적 제어 이론이 사용하는 비용/가치 함수(Cost/Value Function) 대신 사전 선호(Prior Preference)나 기대 자유 에너지(Expected Free Energy)와 같은 베이지안 개념을 사용한다.
(4)효용과 의사 결정
능동 추론과 최적 제어 이론, 경제 이론, 강화 학습은 모두 행동을 선택하는 데 비용(Cost)/보상(Reward)을 활용하지만, 접근 방식에 차이가 있다. 최적 제어 이론과 강화 학습은 비용 함수(Cost Function)와 벨만 방정식(Bellman Equation)을 사용하여 행동을 최적화하고, 경제 이론은 효용 극대화(Utility Maximization)를 목표로 한다. 반면, 능동 추론은 기대 자유 에너지 최소화(Expected Free Energy Minimization)를 목표로 하며, 이는 탐색-활용 딜레마(Exploration-Exploitation Dilemma)을 자연스럽게 해결하는데 도움을 준다. 또한, 비용 개념을 사전 선호(Prior Preference)로 흡수하여 제어의 목적을 명시하고 생성 모델을 편향(Biased)시키며, 가치 함수(Value Function) 대신 사전 확률(Prior)을 사용해 최적 정책을 찾는다. 이렇게 함으로써, 능동 추론은 행동을 예측적 제어를 통해 수행하고, 목표 상태를 더 효과적으로 달성할 수 있게 한다.
Bayesian Decision Theory 베이지안 의사결정 이론(Bayesian Decision Theory)은 미래 결과의 확률을 예측하는 베이지안 계산과 미래 계획에 대한 선호도를 정의하는 효용(Utility) 또는 비용(Cost) 함수를 결합하여 최적의 행동을 선택한다. 반면, 능동 추론은 사전 분포(Prior)가 유기체에게 가치 있는 것을 직접적으로 신호하며, 변분 자유 에너지(Variational Free Energy) 및 기대 자유 에너지(Expected Free Energy)를 최소화하여 신념을 최적화한다. 완전 계급 정리(Complete Class Theorem)에 따르면, 임의의 의사결정과 비용 함수에 대해 베이즈 최적의 결정을 지원하는 사전 분포가 반드시 존재하기 때문에, 베이지안 의사결정 이론은 사전 신념과 비용 함수를 따로 다룰 때 이중성(Duality) 내지 하자(Degeneracy)의 문제가 발생한다. 능동 추론은 이를 선호도(Preference)로 통합하여 해결한다.

Reinforcement Learning 강화 학습(RL)은 시도와 오류(Trial-Error)를 통해 정책(Policy)을 학습하며, 보상(Reward)과 가치 함수(Value Function)를 사용하여 최적의 행동을 선택한다. RL은 가치 함수를 직접 학습하는 모델 프리(Model-Free) 방법, 모델을 학습하여 이를 활용한 데이터로 가치 함수와 정책을 학습하는 모델 기반(Model-Based) 방법, 가치 함수 없이 직접 정책을 최적화하는 정책 그래디언트(Policy Gradient) 방법으로 나뉜다. 반면, 능동 추론은 보상과 가치 함수 대신 변분 자유 에너지와 기대 자유 에너지를 최소화하여 신념을 최적화한다. RL은 행동을 시도와 오류 학습을 통해 강화에 의해 매개된다고 가정하지만, 능동 추론은 행동이 추론의 결과라고 가정한다. 또한, RL에서는 목표 지향적(goal-directed) 행동과 습관적(habitual) 행동이 각각 모델 기반과 모델 프리 RL로 대응되어 병렬로 습득되어 경쟁하는 반면, 능동 추론에서는 목표 지향적 정책을 반복적으로 추구함으로써 습관이 습득될 수 있기에 협력할 수 있다.

Planning as Inference 지각의 문제를 추론의 문제로 보았듯이, 제어 및 계획의 문제 또한 추론의 문제로 보는 것이 가능하다. 이는 Rawlik, Levine의 추론으로써 제어(Control As Inference) 및 Attias, Botvinick, Toussaint의 추론으로써 계획(Planning As Inference), Kappen의 리스크 민감성 및 KL 제어(Risk-Sensitive, KL Control)과 관련되어 있다. 능동 추론과 기타 “추론으로써 계획” 이론은 모두 동적 생성 모델(Dynamic Generative Model)을 사용하여 상태와 행동 간의 확률적 연관성을 인코딩하고 행동 시퀀스를 추론하지만, (1)추론 방법(Inference Method)-(2)추론 대상(Inference Target)-(3)추론 목표(Inference Goal)의 세 가지 주요 차원에서 차이를 보인다. 능동 추론은 (1)변분 추론(Variational Inference)을 사용하여 확장 가능하고 효율적인 계산을 수행하며, (2)모델 기반 예측(Model-Based Planning) 내지, 행동 시퀀스(Action Sequence) 또는 정책(Policies)에 대한 사후 분포(Posterior)의 추론을 제공하고, (3)기대 자유 에너지를 최소화하여 더 넓은 목표를 추구한다. 반면, 기타 이론들은 샘플링과 같은 다른 추론 방식을 사용하고, 단일 행동이나 행동 시퀀스에 중점을 두며, 보상을 극대화하는 것을 목표로 한다.
(5)행동과 제한된 합리성

능동 추론에서는 행동의 신중한(Deliberative)-지속적인(Perseverative)-습관적인(Habitual) 측면을 자동으로 결합한다. 예를 들어, 한 사람이 상점에 가는 동안 예상 자유 에너지를 최소화하여 신중한 계획을 세우고, 변분 자유 에너지를 최소화하여 현재 행동을 지속하며, 과거의 경험에 기반한 습관적 행동을 수행한다. 이는 카너먼의 이중 체계 이론(Dual System Theory)과 달리, 신중한 행동과 지속적 행동, 습관적 행동이 공존하며 상황에 따라 협력할 수 있음을 의미한다. 신중한 행동은 복잡성 비용을 수반할 수 있는 인지 자원에 따라 달라지며, 제한된 합리성 개념에 따라 계산의 비용, 노력, 시의적절성을 균형 있게 맞추는 것이 중요하다. 능동 추론은 행동을 추론의 결과로 보며, 다양한 상황에서 최적의 행동을 유도한다.
자유 에너지 이론과 제한된 합리성 제한된 합리성(Bounded Rationality)은 헬름홀츠 자유 에너지 최소화(Helmholtz Free Energy Minimization)의 관점에서 설명되며, 이는 능동 추론에서 사용되는 변분 자유 에너지 개념과 관련된다. 자유 에너지의 두 구성 요소인 에너지;정확성(Energy; Accuracy)와 엔트로피;복잡성(Entropy;Complexity) 간의 타협을 통해 행동 선택의 상충 관계(Trade-Off)를 설명한다. 능동 추론에서는 신념의 신뢰도(Precision)를 높이는 데 드는 비용과 정확성 간의 타협을 통해 자유 에너지를 최소화한다. 제한된 합리성의 개념은 변분 경계(Variational Bound)를 사용하여 증거(Evidence)를 평가하는 능동 추론과 공명한다. 결과적으로, 능동 추론은 정확성과 복잡성 간의 타협을 통해 최적의 해결책을 도출하는 (제한된) 합리성((Bounded) Rationality)과 최적성(Optimality)의 모델을 제공한다.
(6)감정가, 감정, 그리고 동기
능동 추론은 (음의) 자유 에너지를 생물의 목표 실현 능력의 척도로 사용하며, 생명체는 자유 에너지의 값을 알 필요 없이 기울기를 따라 행동을 조정하는 셈이다. 감정가(Emotional Valence)는 자유 에너지의 시간에 따른 변화율로 설명되며, 자유 에너지의 감소는 양적(Positive) 감정가, 증가는 부적(Negative) 감정가으로 해석된다. 더 나아가, 고차 변화율을 통해 더 복잡한 감정 상태를 설명할 수 있다; 안도감(Relief)은 낮은 감정가에서 높은 감정가로 전환되는 것으로, 실망감(Dissapointment)은 높은 감정가에서 낮은 감정가로 전환되는 것이다. 이는 신뢰도(Precision)와도 관련되는데, 자유 에너지의 2계 변화율이기 때문이다. 자유 에너지의 증가 또는 감소에 대한 기대는 동기 부여와 행동 선택에 중요한 역할을 한다. 정책에 대한 신념의 신뢰도은 도파민 신호와 연결되어, 신뢰할 만한 정책이 발견되면 도파민 폭발이 발생할 수 있다. 목표나 보상 달성에 대한 기대가 주의력(Attention)과 동기 부여(Motivation)의 증가에 연결되는 신경생리학적 메커니즘을 밝히는 데 도움이 될 것으로 기대된다.
(7)항상성, 이상성, 그리고 내수용감각
능동 추론은 생물의 내부 상태(Internal Milieu)를 설명하고 조절하는 생성 모델을 사용하여 항상성(Homeostasis)을 유지한다. 내부수용적 추론(Interoceptive Inference)을 통해 자율 반사(Autonomic Reflex)를 활성화하여 생리학적 매개 변수를 조절하고, 기대 자유 에너지를 최소화하는 이상성(Allostasis) 전략을 사용하여 내수용성 예측 오류를 사전에 방지한다. 생리학적 조절은 정동(Affect) 및 정서(Emotion) 처리에 중요한 역할을 하며, 외부 자극의 인식 동안 발생하는 내부수용 정보의 흐름은 상황의 정동적 의미를 부여한다. 정서 추론(Emotional Inference)은 감정을 생성 모델의 일부로 간주하여 신념을 갱신하고 행동을 조절한다. 예를 들어, 불안은 “나는 불안하다”는 베이지안 신념을 통해 감각 입력 및 내부수용적 신호를 설명하며, 그러한 예측은 신뢰도(Precision)를 조정하거나 자율 반응을 유도한다. 보통, 내부수용적 및 외부수용적 감각 정보는 통합되며, 질병 연구를 통해 감정, 내부수용적 추론(Interoception), 주의집중(Attention) 간의 밀접한 관계를 형성한다.
(8)주의집중, 현저성, 그리고 인식론적 동역학
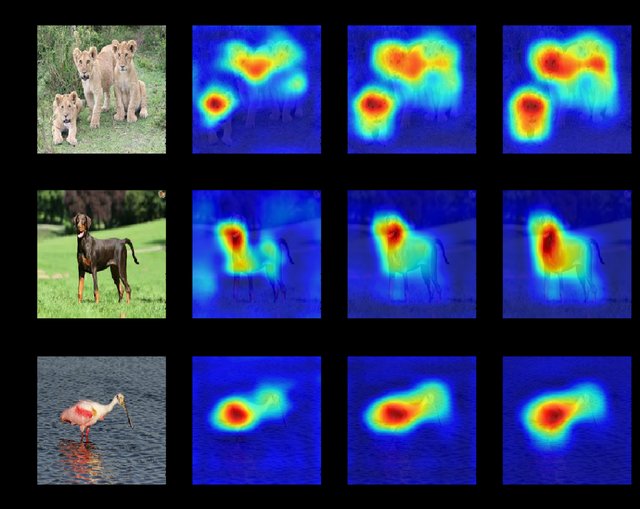
주의집중(Attention)과 현저성(Salience)은 심리학에서 중요한 개념으로, 능동 추론에서는 주의집중을 감각 입력의 신뢰도(Precision)로, 현저성을 기대 정보 이득(Expected Information Gain) 또는 인식론적 가치(Epistemic Value)으로 정의한다. 주의집중은 신념 갱신에 더 큰 영향을 미치는 감각을 선택하는 것이며, 현저성은 더 많은 정보를 제공할 것으로 기대되는 자극을 나타낸다; 주의집중은 추론의 잠재성(Potential to Infer), 현저성은 학습의 잠재성(Potential to Learn)이다. 비유하자면, 주의집중은 이미 측정한 데이터 중에서 가장 높은 품질의 데이터를 선택하여 가설 검정에 사용하는 과정이고, 현저성은 다음 실험을 설계하여 가장 높은 품질의 데이터를 확보하는 과정이다. 능동 추론의 공식적 접근 방식은 주의집중과 현저성의 모호성을 해결하고, 이 두 개념이 종종 혼동되는 이유를 설명한다. 인식론적 동역학(Epistemic Dynamics)은 이러한 개념들이 정보 획득과 행동 결정에 어떻게 영향을 미치는지를 설명한다.
(9)규칙 학습, 인과 추론, 빠른 일반화
능동 추론의 학습 패러다임은 행동(Actions), 사건(Events), 관찰(Observation) 간의 인과 관계(Causal Relations)를 포착하는 생성 모델의 개발에 기반을 둔다. 인간은 복잡한 인과 추론(Causal Inference)과 일반화(Generalization)를 통해 환경의 숨겨진 규칙(Latent Structure)을 학습하며, 이는 단순한 패턴 인식에 기반을 둔 현재의 기계 학습 접근 방식과 대조된다. 숨겨진 규칙을 학습하면 더 나은 예측력과 더 적은 감각적 세부 사항으로도 일반화할 수 있다. 이러한 능력은 새로운 상황에서도 효율적인 학습을 가능하게 하며, 학습을 학습하는(Learning-to-Learn) 능력을 개발한다. 능동 추론은 모델의 정확성(Accuracy)과 복잡성(Complexity) 간의 균형을 맞추는 것을 중요시하며, 모델 축소(Model Reduction)는 단순히 자원을 낭비하는 것을 예방하는 것뿐만 아니라, 숨겨진 규칙을 학습하는 효과적인 방법이다.
(10)기타 활용방안
능동 추론은 생존(Survival)과 적응(Adaptation) 외에도 사회 및 문화 역학(Social and Cultural Dynamics), 기계 학습 및 로봇공학(Machine Learning and Robotics) 등 다양한 분야에 적용될 수 있다. 사회 및 문화 역학에서는 에이전트 간 상호작용의 효과를 탐구하고, 기계 학습 및 로봇공학에서는 이론과 호환되는 방식으로 더 복잡한 문제를 해결하기 위한 학습 메커니즘을 연구한다.
Social and Cultural Dynamics 인간 인지는 개별적 인식보다 사회적 및 문화적 역학과 관련이 깊다. 사회적 역학은 팀 스포츠 같은 물리적 상호작용에서 선거 같은 추상적 상호작용까지, 여러 능동 추론 에이전트를 상호작용을 필요로 한다. 간단한 시뮬레이션은 소멸에 저항하는 간단한 생명체의 자기 조직(Self-Organization), 신체 혀애를 획득하고 복구하는 형태 형성(Morphogenetic Process)의 가능성, 상호 조정된 예측(Mutual Coordinated Prediction) 및 순서 교대(Take Turning)와 같은 흥미로운 발생 현상을 이미 보여주었다. 이러한 연구는 인지가 두개골을 넘어 사회적 틈새로 확장되는 가능성을 시사한다. 능동 추론은 개인의 과학에서 사회의 과학으로 확장될 수 있는 잠재력을 가지고 있다.
Machine Learning and Robotics 기계 학습 및 로봇 공학에서 생성 모델링(Generative Model)과 변분 추론(Variational Inference) 방법이 널리 사용된다. 초기 연결주의(Connectionist) 생성 모델인 헬름홀츠 머신(Helmholtz Machine)과 볼츠만 머신(Boltzmann Machine)은 신경망의 내부 표상(Internal Representation)을 비지도 방식(Unsupervised)으로 학습하는 방법을 제공했으며, 이는 변분 접근과 관련이 깊다. 최근 모델인 변분 오토인코더(VAE)와 생성적 적대 신경망(GAN)은 그림과 비디오를 인식하거나 생성하는 데 널리 사용된다. VAE는 데이터의 정확한 설명을 학습하며 복잡성을 최소화하고, GAN은 생성 네트워크와 판별 네트워크 간의 경쟁을 통해 고품질 데이터를 생성한다. 생성 모델은 로봇의 고차원 움직임 제어(Control)에도 사용되며, 자율 탐색(Autonomous Exploration), 인간의 시연(Demonstration), 인간과의 상호작용을 통해 학습할 수 있다. 능동 추론은 이러한 문제를 해결하기 위한 효과적인 접근 방식을 제공하며, 더 발전된 로봇 기술 개발에 기여할 수 있다.
Summary
대니얼 데닛의 비판은 타당하다. 기존의 공학적 문제 해결 패러다임은 인지 기능의 하위 시스템을 개별적으로 구현하는 데 주력했지만, 그 결과는 인간 수준의 인공지능과는 거리가 멀었다. 이제 우리는 인간과 동물의 인지 기능을 더 포괄적으로 이해하고, 이를 바탕으로 능동 추론적 에이전트를 개발해야 한다. 이러한 접근은 기존의 단순한 시스템 융합보다 훨씬 더 복잡하고, 에너지 효율적이며, 효과적인 기술로 이어질 것이다. 신경생물학에서 얻은 통찰을 적용하면, 더욱 정교한 인공지능을 구현할 수 있다.
인간 수준의 인공지능 개발은 기술적인 혁신뿐만 아니라, 그 기술이 우리의 생활과 사회에 어떤 영향을 미칠지에 대한 깊은 철학적 성찰도 요구한다. 능동 추론 패러다임은 규범적 접근이기 때문에 과학적으로 반증할 수 없지만, 다양한 배경지식을 통합하고 창의적인 해결책을 발견하는 데 중요한 역할을 할 것이다.


Comments