AI vs. The Brain
“How does AI solve problems that seem too complex for us? Why does AI struggle with tasks that are so simple for us? What does human intelligence look like from the perspective of AI?”
This post is a summary of Professor Sangwan Lee’s book “How AI and the Brain Think.”
1. Capturing an Infinite World in Finite Space
This chapter introduces the dilemma of abstraction and diversity, centered around the binding problem—how we recognize objects like an apple. It provides a historical overview of early AI research, starting with Marvin Minsky’s feedforward networks and the challenges of the Credit Assignment Problem, solved by the Error Backpropagation algorithm.
2. Today’s Success, Tomorrow’s Failure
While the first chapter focused on current problems, the second chapter delves into statistical scenarios in real-world interactions. It introduces Structural Risk Minimization from the perspective of statistical machine learning, discussing Tikhonov Regularization to prevent underfitting/overfitting and introducing Support Vector Machines (SVM) through the Dual Problem.
The pursuit of “model efficiency” to solve the Bias-Variance Tradeoff is also found in the human brain. There’s even a neuron that recognizes the actress Jennifer Aniston [2]! This suggests the concept of sparse representation, where very few active cells are required to stably recognize a concept. This ties into critical periods in developmental cognition and pruning, which are key to energy efficiency—an area where the human brain is at least 400 times more efficient than AI systems.

3. The Balance Between Sensitivity and Insensitivity
Having addressed the basics of abstraction/diversity in the first chapter and the statistical solutions and brain characteristics in the second, the third chapter tackles the Specificity-Invariance Dilemma. To achieve both sensitivity and insensitivity in concept abstraction, three approaches are discussed: (1) filtering, (2) pooling, and (3) locality.
First, (1) filtering uses convolution operations to filter out specific patterns, allowing us to focus on important information while ignoring the rest. Next, (2) pooling or subsampling compresses the information, extracting only what is meaningful. Finally, (3) locality applies to both filtering and pooling, setting the receptive field’s range to focus on significant local information. Such topographic maps also appear in the brain, implying that inductive biases are intentionally applied to enhance the spatial, temporal, and energy efficiency of computation. While the origins of this are still unclear, it is suggested that these traits may have been acquired through evolution.
By combining convolution, pooling, and non-linear functions into building blocks and stacking them in various ways, architectures can be designed to achieve the desired level of abstraction. While this bottom-up approach looks at the whole through its parts, the top-down approach allows us to focus on the parts through the whole, enabled by attention mechanisms. Although Self-Attention has emerged, a clean solution is yet to be found.
Our brain resolves the paradox between parts and the whole through bottom-up concept abstraction and top-down attention. A mechanism exists that can capture high-level concepts even from the lowest layers. This is possible thanks to the nonlinearity of retinal neurons, where the density decreases from the center to the periphery, guiding top-level attention by leveraging low-dimensional peripheral information.
- Brain -> AI:
- It took 20 years for CNNs, reflecting the computational principles of the cerebral cortex, to achieve great success.
- Brain science could have accelerated this process.
- AI -> Brain:
- The functional similarity between CNNs and brain function highlights how the brain processes information at each layer, showing a mutually beneficial relationship.
- Predictive Coding Scheme, Illusion?
| Questions:
- If artificial neural networks are functionally similar to the brain, could we observe similar phenomena from an introspective perspective as well? How do human optical illusions relate to phenomena in artificial neural networks?
- Does the local arrangement of representations in the cerebral cortex genuinely enhance the spatial, temporal, and energy efficiency of computation? Could this be verified through computational models and simulations?
4. The Subjective is So Objective
Chapters 1-3 focused on how we abstract and understand the world based on observed results. Chapter 4 shifts to the opposite direction—concretization, with a focus on data generation. Unlike the deterministic neural networks discussed earlier, we now explore probabilistic neural networks where each neuron is replaced by a random variable.
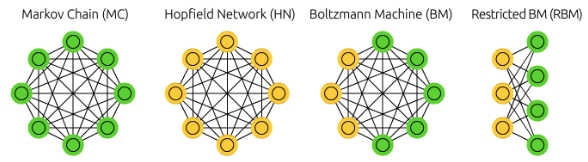
An early example of probabilistic neural networks is the Hopfield Network, which allows not only simple statistical analysis but also complex correlation analysis. Probabilistic neural networks are advantageous because they (1) allow easy inference, (2) explain the roles of each element, (3) highlight the risks of ignoring certain elements, and (4) detect intricate interrelationships.
The Boltzmann Machine, which adds hidden neurons to the Hopfield Network, allows hypotheses to be tested based on data. Its goal is to learn the correlations between various factors in the data. It does this by deriving learning rules to find the optimal weights that connect neurons, minimizing the difference between (1) observable correlations in the data and (2) the correlations learned by the network. The former is akin to being in a wakeful state, directly observing data, while the latter is like a dream state, where the network infers without direct data observation—hence, the Wake-Sleep Rule.
To address the difficulty of applying probabilistic neural networks in practice, the Restricted Boltzmann Machine (RBM) was developed. RBM allows connections only between visible and hidden neurons, eliminating complex correlations among hidden neurons. The structure of visible and hidden neuron layers forms a building block, leading to the development of Deep RBM (DRBM). When combined with the error backpropagation algorithm for precise learning, it becomes the deterministic Autoencoder (AE).
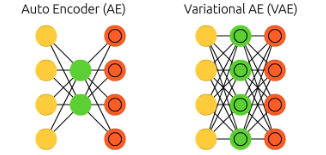
Autoencoders use symmetry to achieve abstraction and concretization, a principle also seen in Principal Component Analysis (PCA). Today, even if symmetry is broken, it is utilized within mathematically permissible limits. The probabilistic version of the autoencoder, the Variational Autoencoder (VAE), (1) retains some symmetry of the autoencoder, (2) adds depth to the abstraction process, and (3) increases the density of the concretization process. Lastly, the Reparametrization trick is applied, allowing the error backpropagation algorithm to be used.
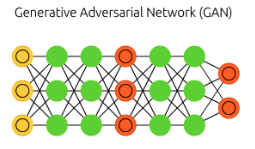
Ultimately, the performance of abstraction and concretization is evaluated by the error function defined by the user. To objectify this self-assessment, game theory is employed, leading to models like the Generative Adversarial Network (GAN). From an information theory perspective, traditional deterministic networks like PCA and autoencoders learn by minimizing KL Divergence. Unlike the asymmetric KL Divergence, GAN minimizes the symmetric JS Divergence, which can be viewed as an Optimal Transport problem in economics and evaluated using the Wasserstein Distance.
| Questions:
- How do these probabilistic neural networks relate to the human brain? Are neurons treated as random variables because of their inherent randomness, or is this merely an assumption?
- How do recent diffusion-based generative models like StableDiffusion relate to the models discussed above?
- How are they connected to the Ising Model in statistical mechanics or Cellular Automata?
5. Predicting the Past and Remembering the Future
Chapters 1-3 covered concept abstraction, Chapter 4 dealt with concept concretization, and now, Chapter 5 focuses on memory—taking concepts on a journey through time. Previously, the i.i.d condition for data was assumed, but in reality, most events are not independent. Therefore, remembering concepts generated in the past becomes crucial. A strategy to implement this is feedback. One of the most common neurons found in the cerebral cortex, hippocampus, and other areas is the Pyramidal Neuron, which receives input not only from nearby neurons but also from distant neurons it has already communicated with! In Recurrent Neural Networks (RNN), applying the backpropagation algorithm can lead to problems like the exploding gradient or vanishing gradient, making learning difficult. To address these issues, Long-Short Term Memory (LSTM) was developed.
The ideal neural network that can flexibly accept new information while maintaining stable memory would (1) adapt to situations and (2) expand its knowledge. This is known as Continual Learning or Lifelong Learning. Moreover, this adaptability makes it useful for Multi-Domain Adaptation and Multi-Task Learning.
Artificial neural networks lack this fluid memory capability, leading to a phenomenon called Catastrophic Forgetting, where past learning evaporates in pursuit of new information. To mitigate this, techniques like (1) regularization, (2) leveraging past data, and (3) parameter utilization can be applied. However, the Transformer model, which uses Self-Attention, eliminates the distinction between past and future events in space and time. As the author puts it, “predict the past and remember the future!”
The Transformer model is also effective in addressing the problem of concretizing memory discussed in Chapter 4. While abstraction involves comprehensively understanding events in sequence, concretization requires reconstructing events in the correct order. The memory concretization network aims to reinterpret and reorder events according to the given context. Techniques like Attention Masking allow the model to focus only on the inputs received so far, enabling high performance in models like BERT and GPT.
| Questions:
- How does the human brain solve the problem of Catastrophic Forgetting?
- Does the Transformer model truly leverage the AE and Attention mechanisms effectively? (In the case of the World Model, it consists of VAE+RNN+Controller.)
- What are the computational and training efficiencies of the Transformer model? Can it be used effectively on a standard GPU?
- Is the Transformer model efficient from a neuroscience perspective?
6. Thinking Beyond Time and Space
Chapters 1-3 focused on concept abstraction, Chapter 4 on concept concretization, Chapter 5 on memory, and now, Chapter 6 deals with the learning principles of neural networks. The error backpropagation algorithm, used in the weight transport process of current neural networks, relies on Bellman’s Dynamic Programming—a sort of "God Mode." But does our brain really operate this way?
Research from DeepMind suggests that even removing weight information and training with random numbers using only Feedback Alignment can enable learning! At least biological neural networks do not learn according to a God Mode error backpropagation algorithm.
The Synaptic Plasticity of a neuron consists of the overall changes through (1) Long-Term Potentiation and (2) Long-Term Depression. These changes are caused by the relative timing differences that result from the dynamic response characteristics of the neuron’s dendrites (changes in dendritic sensitivity), indicating that biological neural networks operate more like a "First-Person Mode" rather than a God Mode.
To capture synaptic plasticity in artificial neural networks, researchers developed the Temporal Error Model and later the Predictive Coding Model. The Predictive Coding Model includes error nodes to assess the accuracy of neuron transmission.
On the other hand, dendrites perform a kind of normalization operation. Large dendrites respond insensitively to the input values of various channels, maintaining insensitivity and stability even when the information volume changes significantly. Dendrites with many local connections are called Basal Dendrites, while those with many global connections are Apical Dendrites. Recent research suggests that Basal Dendrites are comparable to shallow artificial neural networks, while Apical Dendrites are akin to deep neural networks with one or more hidden layers.
| Questions:
- Are there learning algorithms based on the dynamic characteristics of synaptic plasticity?
- Can the Critical Brain Hypothesis, which I find intriguing from a physical perspective, explain the phenomenon of Feedback Alignment?
- If we consider a neuron as a random variable, what is the significance of noise?
- Could Active Inference provide an even better explanation than Predictive Coding?
7. Changing the Past by Looking into the Future
Chapters 1-3 covered concept abstraction, Chapter 4 dealt with concept concretization, Chapter 5 focused on memory, and Chapter 6 discussed the learning principles of neural networks. The final chapter, Chapter 7, explores reinforcement learning. At its core, reinforcement learning is about learning strategies or policies for dynamic systems. However, when these strategies are applied, the Temporal Credit Assignment Problem—determining how much past strategies contributed to the current experience—must be addressed.
Bellman’s Dynamic Programming and the Principle of Optimality are some ways to solve this problem by recursively breaking down complex problems into simpler ones. More specifically, Bellman’s equations are defined over a Markov Decision Process, and reinforcement learning is performed using the reward prediction error derived from the environment.
Reinforcement learning algorithms like AlphaGo solve problems using Model-Free Reinforcement Learning (MFRL). However, analyzing AlphaGo’s habitual behavior reveals Devaluation Insensitivity—a fixation on results. MFRL struggles with flexibility when goals need to change. In contrast, animals typically display goal-oriented behavior. Research from 1977 (Wolfram Schultz, Peter Dayan, Read Montague) revealed that changes in dopamine neuron activity in monkeys resemble the reward prediction error signals in Model-Free learning algorithms. In 2004, the human striatum was identified as the central region for MFRL!
To overcome these shortcomings, Model-Based Reinforcement Learning (MBRL) was proposed, which separates goals from principles, allowing for diverse goals in various situations. However, this model struggles when problems are too complex or environmental uncertainty is high, making it difficult to learn the model. Like MFRL, MBRL has a deep scientific history. Research from the 1930s (Edward Tolman) showed that rats could engage in latent learning even without rewards, forming a Cognitive Map of the environment. This learning occurs through state prediction errors arising from discrepancies between expected and actual situations. It was later discovered that the Limbic System in rats and the Lateral Prefrontal Cortex and Intraparietal Sulcus in humans are central to MBRL.
Meanwhile, Model Predictive Control in optimal control theory, which uses model-based methodologies, is considered the origin of model-based learning. In behavioral economics, the quick, semi-automatic decision-making style like MFRL is known as “System 1,” while the conscious, slow decision-making style like MBRL is referred to as “System 2.”
In 2005, a research team at University College London posed an even bolder question: could the brain switch between MFRL and MBRL depending on the uncertainty in predicting outcomes? Indeed, in 2015, it was revealed that the Lateral Prefrontal Cortex and Frontopolar Cortex in humans process this uncertainty information and control the learning process by combining the two strategies! In other words, this meta-cognitive process allows us to “read the situation,” focus on the “task,” and adapt our learning strategies accordingly.
| Questions:
- Let’s explore the advantages and disadvantages of MBRL and MFRL.
- Are these two paradigms truly analogous to Daniel Kahneman’s System I vs. II?
- Does meta-cognition imply higher-order thinking? Is the switching principle between MBRL and MFRL merely secondary thinking?
- Can Active Inference offer a more comprehensive theory?
References
[1] “How AI and the Brain Think,” by Sangwan Lee, Sol Publishing, 2022
[2] There Are Neurons that Recognize Faces, The Science Times, Sim Jaeyul, Guest Reporter, 2019 2/12
[3] Van Veen, F., & Leijnen, S. (2019). The Neural Network Zoo. The Asimov Institute. https://www.asimovinstitute.org/neural-network-zoo/


Comments