Toward Fast and Robust Autonomous Driving
“We live in a world that is complex, nonlinear, and uncertain. How can we develop strategies to navigate this chaotic environment and ensure our survival? And can we enable robots to learn and discover such strategies on their own?”
Think about vehicles, robots, or even nuclear power plants. These are all systems composed of smaller components like sensors, bolts, nuts, and motors. We expect these systems to perform actions as we desire. Take driving as an example: every morning and evening, we use our eyes and ears to perceive near and distant surroundings, adjusting the pressure on the pedal with our right foot to navigate the road. How can we replicate this behavior in machines or software?
This article aims to summarize the insights gained while studying Optimal Control Theory in the context of Autonomous Driving, specifically focusing on Information-Theoretic Model Predictive Control (MPC), a popular algorithm in the field of Model Predictive Control.
1. The Origins of Optimal Control Theory
The effort to control a system in the most efficient way has deep roots in the cybernetics movement and eventually evolved into what is now known as Optimal Control Theory (OCT). OCT provides a theoretical framework and engineering methodologies to guide systems towards the desired optimal actions. It requires a strong mathematical background as it was founded by two mathematical geniuses: Richard E. Bellman from the United States and Lev Pontryagin from the Soviet Union.
1.1 Richard Bellman and Lev Pontryagin


Richard Bellman, famous for his autobiography “Eye of the Hurricane,” worked on missile control problems at RAND Corporation in the 1950s. He is the inventor of Dynamic Programming, a method that simplifies complex problems by breaking them into smaller, recursive problems. Bellman applied this technique to the Hamilton-Jacobi Equation, which describes the motion of particles in terms of waves. This led to the Hamilton-Jacobi-Bellman (HJB) Equation, commonly referred to as the HJB equation.
On the other hand, Lev Pontryagin, despite being blind, made remarkable contributions across various fields. He is best known for Pontryagin’s Maximum Principle, which, like Bellman’s approach, derives similar results using rigorous mathematics. His work was later applied to economics by Nobel laureate Leonid Kantorovich. Pontryagin’s approach involved solving optimal control problems using differential equations, which had limitations due to boundary conditions. Bellman’s approach, using partial differential equations, was more flexible but still faced challenges like the curse of dimensionality.
1.2 Discrete-Time Optimal Control Problems
An Optimal Control Problem consists of three key components. First, there must be a dynamic system that evolves over time, space, and control variables. Let’s consider a dynamic system in discrete time. Let the time variable be denoted by $t$, the system state by $x_t$, and the control input by $u_t$. In the equation below, $f$ represents the dynamics of the system:
\[x_{t+1} = f(t, x_t, u_t), \ \ t= 0,1,...,T \cdots (1)\]This dynamic system incurs a reward (Bellman) or cost (Pontryagin) $R(t,x_t,u_t)$ depending on the time, state, and control input. The total cost over the given time horizon can be expressed as $C(x_0, u_{0})$. The reason the total cost $C(x_0, u_{0})$ only depends on the initial system state $x_0$ and the control inputs $u_{0}$ is twofold. First, given the initial conditions and the subsequent control inputs, the entire trajectory of the system can be computed through the dynamics $f$. Second, in practical scenarios, the system state at each time step is often inferred through sensors, so assuming that only the initial state is known makes sense:
\[C(x_0, u_{0:T}) = \sum_{t=0}^{T} R(t,x_t,u_t) \cdots (2)\]Next, we can define the optimal control that minimizes the total cost. The optimal control $J(t, x_t)$ is the control input that minimizes the cost from the current time $t$ to a future time $T$. In other words:
\[J(t, x_t) = \min_{u_{t:T}} \sum_{s=t}^{T} R(s,x_s,u_s) \cdots (3)\]The optimal control follows a recursive relationship. This becomes clear through the expansion of the equation below, which shows that $J(t,x_t)$ can be computed from $J(t+1,x_{t+1})$:
\[\begin{align} \underline{J(t,x_t)} & = \min_{u_{t:T}} \sum_{s=t}^{T} R(s,x_s,u_s) \ by\ definition \\ & = \min_{u_t}\left( R(t,x_t,u_t) + \min_{u_{t+1:T}} \sum_{s=t+1}^{T} R(s,x_s,u_s) \right) \\ & =\min_{u_t}\left( R(t,x_t,u_t) + J(t+1, x_{t+1}) \right) \\ & =\min_{u_t}\left( R(t,x_t,u_t) + \underline{J(t+1, f(t,x_t,u_t))} \right) \cdots (4) \end{align}\]Using this relationship, we can apply Bellman’s dynamic programming approach: starting from the desired final state at time $T$, where $J(T+1,x)=0$, we work backward in time to calculate the optimal control inputs.
1.3 Continuous-Time Optimal Control Problem
Just like the optimal control problem in discrete time described by equations (1), (2), (3), and (4), we can consider a system in continuous time with real variables $x$ and $u$. The elements of the problem can be expressed as follows, where $\phi(x(t_f))$ represents a terminal cost associated with the final state of the system:
\[\begin{align} \dot{x} & = f(x,u,t) \cdots (5)\\ C(t_i, x_i, u(t_i \rightarrow t_f)) & = \phi(x(t_f)) + \int_{t_i}^{t_f} dt R(x(t),u(t),t) \cdots (6)\\ J(t,x) & = \min_{u(t_i \rightarrow t_f)} C(t,x,u(t \rightarrow t_f)) \cdots (7)\\ \end{align}\]Next, the optimal control $J(t,x)$ follows a recursive relationship, just like in equation (4). While the detailed derivation is omitted, the recursion is shown below:
\[\underline{J(t,x)} = \min_{u(t \rightarrow t')} \left( \int_{t}^{t'} dt R(x(t),u(t),t) + \underline{J(t', x(t'))} \right) \cdots (8)\]Now, assuming $t’$ is a small increment after $t$, i.e., $t’ = t + dt$, and taking the limit as $dt \rightarrow 0$, we derive the following partial differential equation, known as the Hamilton-Jacobi-Bellman (HJB) equation:
\[\begin{align} - J_t(t,x) & = \min_{u} \left( R(x,u,t) + J_x(t,x)f(x,u,t) \right) \\ J(x,t_f) & = \phi(x) \end{align} \cdots (9)\]2. The Development of Stochastic Optimal Control Theory

While traditional optimal control theory provides a solid theoretical framework, the process of solving these problems computationally can be incredibly time-consuming. Moreover, there are limitations when it comes to estimating the dynamics model $f$, measuring the true value of the variable $x$, or applying the correct input $u$. It was in this context that Dutch physicist Hilbert J. Kappen introduced a solution by adding noise terms to the HJB equation.
Kappen, a professor at Radboud University in the Netherlands, specializes in The Physics of Machine Learning within the field of biophysics. But what exactly is the noise that Kappen introduced?
2.1 Wiener Process


In mathematics, the Wiener process is a continuous-time stochastic process discovered by American mathematician Norbert Wiener, who is also known as the father of cybernetics. The Wiener process is closely related to Brownian motion, which Einstein studied in the context of the movement of pollen in water. Formally, they share a deep connection. Most natural phenomena contain noise, and the Wiener process is a common feature in many stochastic processes. While traditional optimal control theory relies on deterministic assumptions, real-world problems often require stochastic processes to be accounted for. The Wiener process serves as a mathematically and physically natural representation of noise.
Let’s take a closer look at the mathematical definition of a Wiener process. A stochastic process $W_t$ is called a Wiener process if it satisfies the following properties:
- $W_0 = 0$.
- For any $t > 0$, the future increments $W_{t+u} - W_t$, with $u \geq 0$, are independent of the past values $W_s$ for $s < t$.
- $W_{t+u} - W_t \sim \mathit{N}(0, \nu)$.
- $W_t$ is continuous with respect to $t$.
Regarding calculus, the infinitesimal change in the Wiener process, $d\xi$, has the following property. This aligns with a conclusion Einstein reached in his study of Brownian motion, where the mean square displacement is proportional to time. The property is described as follows:
\[<d\xi^2> = \nu dt \cdots (10)\]2.2 Stochastic Optimal Control Problem
We can now add a noise term based on the Wiener process to the continuous-time optimal control problem previously described in equations (5), (6), (7), and (8). The resulting stochastic optimal control problem can be described as follows, and in equation (13), we again observe a recursive relationship:
\[\begin{align} dx & = f(x(t),u(t),t)dt + d\xi \cdots (11)\\ C(t_i, x_i, u(t_i \rightarrow t_f)) & = \biggl< \phi(x(t_f)) + \int_{t_i}^{t_f} dt R(x(t),u(t),t) \biggr>_{x_i} \cdots (12)\\ \underline{J(t,x)} & = \min_{u(t_i \rightarrow t_f)} \biggl< \int_{t}^{t'} dt R(x(t),u(t),t) + \underline{J(t', x(t'))} \biggr>_{x} \cdots (13)\\ \end{align}\]When we assume that $t’$ is an infinitesimally small time step after $t$, i.e., $t’ = t + dt$, and take the limit as $dt \rightarrow 0$, we obtain the following partial differential equation. In this derivation, we apply equation (10), replacing the mean square of the noise term $<d\xi^2>$ with the variance of the Wiener process, $\nu dt$. The resulting equation is known as the Stochastic Hamilton-Jacobi-Bellman Equation (sHJB):
\[\begin{align} - \partial_{t} J(t,x) & = \min_{u} \left( R(x,u,t) + f(x,u,t)^{T} \partial_{x} J(t,x) + \frac{1}{2}\nu \partial_{x}^2J(t,x) \right) \\ J(x,t_f) & = \phi(x) \end{align} \cdots (14)\]3. Path Integral Framework
The sHJB equation derived above is a nonlinear partial differential equation (PDE), making it challenging to obtain a general solution. Kappen proposed an approach that transforms the equation into a path integral form, allowing for approximation solutions through simulations. To convert this equation into a path integral form, we first need to introduce some assumptions.
3.1 Simplification to LQ Problem
To linearize the sHJB problem, we can make a few assumptions to reduce its complexity. The first assumption is the linearization of control inputs within the dynamical system, and the second is the quadratic form of the control input costs. These assumptions simplify the problem into what is known as a Linear Quadratic (LQ) problem.
To explain more simply, let’s reconsider the stochastic optimal control problem we previously defined. In equation (11), the assumption that the dynamical system is linear with respect to the control input means we can decompose the system function $f$ß into two parts: (1) the part that is independent of the control and (2) the part that is linearly dependent on the control input. Specifically:
\[f(x,u,t) = b(x,t) + Bu\]Similarly, the assumption that the control input has a quadratic relationship with the cost means that the reward term $R(x,u,t)$ in equation (12) can be split into (1) the part that is independent of the control and (2) the part that is quadratically dependent on the control input. That is:
\[R(x,u,t) = V(x,t) + \frac{1}{2} u^T R u\]Applying these assumptions to the stochastic optimal control problem reduces the equations as follows:
\[\begin{align} dx & = \left( b(x,t) + Bu \right)dt + d\xi \cdots (15) \\ C(t_i, x_i, u(t_i \rightarrow t_f)) & = \biggl< \phi(x(t_f)) + \int_{t_i}^{t_f} dt \left( V(x(t),t) + \frac{1}{2} u(t)^T R u(t) \right) \biggr>_{x_i} \cdots (16) \\ \end{align}\]With this setup, we can derive the reduced sHJB equation in a similar manner, leading to the following expression:
\[\begin{align} - \partial_{t} J & = \min_{u} \left( V + \frac{1}{2} u^T R u + (b + Bu)^{T} \partial_{x} J + \frac{1}{2} \mathrm{Tr} \left( \nu \partial_{x}^2J \right) \right) \\ J(x,t_f) & = \phi(x) \end{align} \cdots (17)\]Using Rolle’s Theorem, we can solve for the control input $u$ that makes the right-hand side zero. This yields the following expression (the derivation is omitted):
\[u=-R^{-1}B^T \partial_{x} J(x,t)\]Substituting this candidate solution into the right-hand side of equation (17) gives the reduced equation:
\[\underline{- \frac{1}{2} (\partial_{x} J)^T BR^{-1}B^T (\partial_{x} J)} + V + b^{T} \partial_{x} J + \underline{\frac{1}{2} \mathrm{Tr} \left( \nu \partial_{x}^2J \right)} \cdots (18)\]3.2 Log Transformation
As we can see, even after reducing the sHJB equation using LQ assumptions, we still have a nonlinear equation with second-order derivatives with respect to $J$ (as highlighted in equation (18)). To linearize this equation, we can apply a log transformation. Specifically, we introduce a new function $\psi$ to replace $J$. The constant $-\lambda$ is introduced to facilitate future calculations:
\[J(x,t) = - \lambda \log \psi(x,t) \cdots (19)\]Substituting this transformation into the underlined quadratic terms in equation (18), we get the following:
\[\begin{align} - \frac{1}{2} (\partial_{x} J)^T BR^{-1}B^T (\partial_{x} J) + \frac{1}{2} \mathrm{Tr} \left( \nu \partial_{x}^2J \right) & = \underline{- \frac{\lambda^2}{2 \psi^2} \sum_{i, j} (\partial_x \psi)_i (BR^{-1}B^T)_{i,j}(\partial_x \psi)_j}\\ & \quad +\underline{\frac{\lambda^2}{2 \psi^2} \sum_{i, j} \nu_{i,j} (\partial_x \psi)_i (\partial_x \psi)_j} \\ & \quad -\frac{\lambda}{2 \psi} \sum_{i,j} \nu_{i,j} \frac{\partial^2 \psi}{\partial x_i \partial x_j}. \end{align}\]To ensure this equation becomes linear, the sum of the first two underlined terms must equal zero. This leads to the necessary and sufficient condition of the existence of an appropriate scalar $\lambda$. In other words, we need to determine which scalar value for the log transformation is appropriate. Formally, the condition is derived as follows:
\[\exists \ a\ scalar\ \lambda \mid \nu = \lambda B R^{-1} B^T \cdots (20)\]3.3 Kolmogorov Backward Equation
If we assume an appropriate scalar $\lambda$ that satisfies equation (20), we can apply the log transformation, resulting in a linear equation. The overall reduced sHJB equation now takes the following form, which is a Kolmogorov Backward Equation, named after the Soviet mathematician Andrey Kolmogorov. This PDE is widely used in the study of continuous-time, continuous-state Markov processes, providing insights into how future states can be inferred from the current state of a system:
\[\begin{align} - \partial_t \psi & = H\psi,\ where\ an\ operator\ H = \left( \frac{V}{\lambda} + b^T\nabla + \frac{1}{2} \nu \nabla^2 \right) \end{align} \cdots (21)\]On a related note, the American theoretical physicist Richard Feynman and mathematician Mark Kac, while working on the Manhattan Project, developed the Feynman-Kac formula to calculate the random trajectories of neutrons. This formula allows us to simulate stochastic trajectories, solving PDEs like equation (21). While we won’t go into details here, applying the Feynman-Kac formula leads to the following expression:
\[J(x,t) = -\lambda \log \int [dx]_x \exp{ - \frac{1}{\lambda} S(x(t \rightarrow t_f))} + C \cdots (22)\]Here, $S$ represents the constraints on the final system state as well as the cost of the system’s trajectory over time, with the exact formulation being:
\[\begin{align} S(x(t \rightarrow t_f)) & := \phi(x(t_f)) + \underline{S_{path}(x(t \rightarrow t_f))} \\ & = \phi(x(t_f)) + \underline{\int_{t}^{t_f} d\tau \left( \frac{1}{2} \left( \frac{dx(\tau)}{d\tau} - b(x(\tau), \tau) \right)^T R \left( \frac{dx(\tau)}{d\tau} - b(x(\tau), \tau) \right) + V(x(\tau), \tau) \right)} \end{align} \cdots (23)\]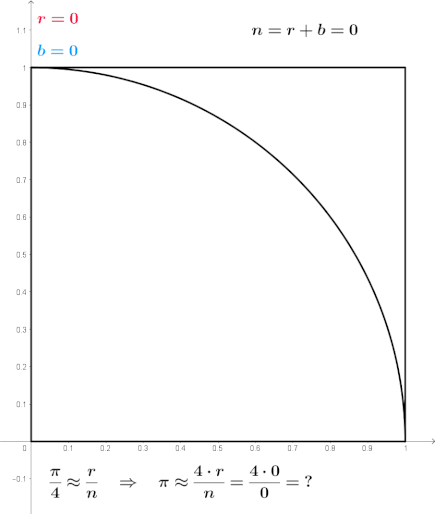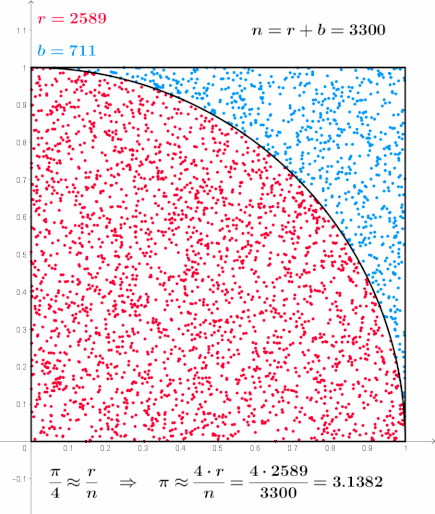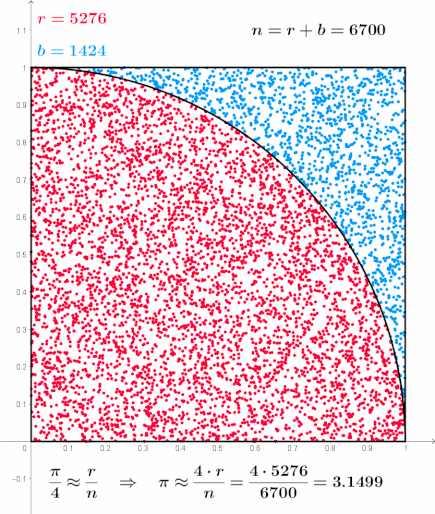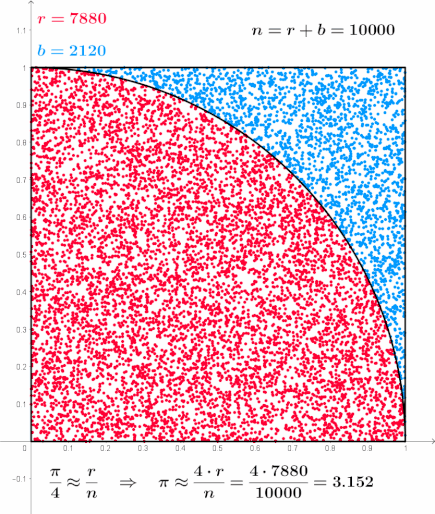
The path integral form above can be computed using statistical sampling methods. In his paper, Kappen applies a simple Monte Carlo Sampling technique to perform simulations.
3.4 Connection to Thermodynamics and Reinforcement Learning
The form of equation (22) is remarkably similar to the concept of free energy in information theory. The log-integral structure inside the equation mirrors the partition function commonly used in statistical mechanics. When combined with the logarithmic operation, the entire equation can be interpreted as thermodynamic free energy.

This framework also shares connections with Reinforcement Learning, which has gained significant attention recently. Reinforcement learning can be seen as an optimal control problem in a stationary environment with discounted future rewards. However, while optimal control theory tends to focus on finite future scenarios, reinforcement learning often deals with infinite futures. Additionally, reinforcement learning uses different terminology, referring to optimal control as “optimal policy” and cost as “value.” Whereas optimal control theory aims to develop effective controllers, reinforcement learning seeks to develop intelligent agents.
4. Information-Theoretic Framework

Hilbert Kappen developed the path integral framework, offering an effective method for solving optimal control problems. His approach evolved from classical optimal control theory into a form more suited for modern scientific computing. On the other hand, Evangelos Theodorou from Georgia Tech takes a reverse approach, deriving the HJB equation from the variational free energy in information theory. To understand this, we first need to grasp the basic concepts of probability and information theory.
4.1 The Free Energy

Before we dive into free energy, we need to discuss information. Information theory, developed by Claude Shannon in the 1940s, quantifies the uncertainty of a given (probabilistic) variable. According to Shannon, for any random variable $X$ with a probability distribution $P_X(X=x)$, the self-information of a specific event $x$ (Self-Information) as $- \log P_X(X=x)$, with this form being unique. The lower the probability of an event, the more uncertain it is, and therefore the more information it carries—matching our intuition. The average of the self-information over all possible events is defined as entropy, representing the average uncertainty of the random variable:
\[\begin{align} I(X=x) & = - \log P_X(X=x) \cdots self-information\ of\ x \\ \mathcal{E}(X) & = \mathbb{E}_{x \sim P_X} \left[ - \log P_X(X=x) \right] \cdots entropy\ of\ X \end{align}\]Free energy is then defined for any probability distribution $\mathbb{P}$ and a measurable function $J$ as follows, using the parameter $\rho \in \mathbb{R}^{\neg 0}$:
\[\mathcal{F} = \log_{e} \int \exp \left( \rho \mathcal{J}(x) \right) \mathbb{d}\mathbb{P} \cdots (24)\]Since we often don’t know the true distribution $\mathbb{P}$, we can introduce $\mathbb{Q}$ within the context of variational inference. The difference between the distributions is expressed using Kullback-Leibler divergence (KL divergence):
\[\begin{align} \mathbb{KL(Q||P)} & = \mathbb{E}_{X \sim Q}\left[ \log{\mathbb{Q}(X)} - \log{\mathbb{P}(X)}\right] \\ & = \int \log_{e} \frac{\mathbb{dQ}}{\mathbb{dP}} \mathbb{dQ} \end{align}\]Incorporating KL divergence into free energy leads to a Legendre transformation inequality, with the equality condition being:
\[\begin{align} - \frac{1}{|\rho|} \log_{e} \mathbb{E_P} \left[ \exp(-|\rho|\mathcal{J}) \right] & \leq \left[ \mathbb{E_Q}(\mathcal{J}) + {|\rho|}^{-1} \mathbb{KL(Q||P)} \right] \\ & = \inf_{\mathbb{dQ}} \left[ \mathbb{E_Q}(\mathcal{J}) + {|\rho|}^{-1} \mathbb{KL(Q||P)} \right],\ when\ \mathbb{dQ^*} = \frac{\exp(- |\rho| \mathcal{J}) \mathbb{dP}}{\int {\exp(- |\rho| \mathcal{J}) \mathbb{dP}} } \end{align} \cdots (25)\]4.2 Optimal Control Problem
Let us formulate the problem based on the conclusions from the previously introduced stochastic optimal control problem and the path integral framework. First, we define the cost function $\mathcal{J}$ as the sum of the cost $\phi(\mathbb{x}(t_N), t_N)$, which depends only on the final state $t_N$, and the operational cost of the trajectory, represented as the integral of the cost function $q(\mathbb{x}, \tau)$ over time, $\int_{t}^{t_N} q(\mathbb{x}, \tau) \mathbb{d}\tau$. The free energy function (Free Energy Function) is then defined by introducing a non-zero real number $\nu \in \mathbb{R}^{\neg 0}$, and taking the logarithm of the exponential average. Here, $\rho > 0$ leads to risk sensitivity, while $\rho < 0$ leads to risk-seeking behavior.
\[\begin{align} \mathcal{J} & = \mathcal{J}(\mathbb{x}(\cdot), t) = \phi(\mathbb{x}(t_N), t_N) + \int_{t}^{t_N} q(\mathbb{x}, \tau) \mathbb{d}\tau \cdots (26)\\ \xi(\mathbb{x}, t) & = \frac{1}{\rho} \log_e \mathbb{E_P} \biggl[ \exp \left( \rho \mathcal{J}(\mathbb{x}, t) \biggr) \right] \cdots (27) \end{align}\]Let us now introduce the system dynamics. Suppose the distribution of the system under control inputs is denoted by $\mathbb{Q}$, while the distribution of the system without any control is denoted by $\mathbb{P}$. Here, $\mathbb{w}$ represents the Brownian noise term.
\[\begin{align} \mathbb{P}^{\mathbf{Controlled}}: \mathbb{dx} & = \mathbf{F} \mathbb{(x,u)} \mathbb{d}t + \mathbf{C} \mathbb{(x)} \mathbb{dw}(t) \\ \mathbb{Q}^{\mathbf{Uncontrolled}}: \mathbb{dx} & = \mathbf{A}\mathbb{(x)} \mathbb{d}t + \mathbf{C} \mathbb{(x)} \mathbb{dw}(t) \end{align} \cdots (29)\]First, define $\delta F$ as follows:
\[\delta \mathbf{F} \mathbb{(x,u)} = \mathbf{F} \mathbb{(x,u)} - \mathbf{A} \mathbb{(x)} = \mathbf{F} \mathbb{(x,u)} - \mathbf{F} \mathbb{(x,0)},\ \forall x, u\]Now, defining $\Sigma_\mathbf{C} = \mathbf{C}\mathbb{(x)}\mathbf{C}\mathbb{(x)}^T$, we can express the Radon-Nikodym derivative between the two probability distributions as follows:
\[\mathbb{\frac{dQ}{dP}} = \exp \biggl[ \int_{t_0}^{t_N} \left( \delta \mathbf{F}^T\mathbf{C}\mathbb{(x)}^{-1}\mathbb{dw(t)} + \frac{1}{2}\delta \mathbf{F}^T\mathbb{\Sigma}_\mathbf{C}^{-1}\delta \mathbf{F} \delta t \right) \biggr] \cdots (30)\]Next, applying the Radon-Nikodym derivative from equation (30) to the Legendre inequality in equation (25), we find that this equality separates into two terms: the state cost, representing the cost $\mathcal{J}$ under $\mathbb{Q}$, and the information cost, representing the Kullback-Leibler divergence between the distributions $\mathbb{Q}$ and $\mathbb{P}$. This demonstrates that the problem is designed to minimize both costs simultaneously, balancing the trade-off between them.
\[\begin{align} - \frac{1}{|\rho|} \log_{e} \mathbb{E_P} \left[ \exp(-|\rho|\mathcal{J}) \right] & \leq \underbrace{\mathbb{E_Q}\left[(\mathcal{J})\right]}_{State\ Cost} + \underbrace{\mathbb{E_Q}\left[\frac{1}{2|\rho|} \delta \mathbf{F}^T\mathbb{\Sigma}_\mathbf{C}^{-1}\delta \mathbf{F} \delta t \right]}_{Information\ Cost} \\ & = \mathbb{E_Q}\left[(\mathcal{J})\right] + \mathbb{E_Q}\left[\frac{1}{2|\rho|} \delta \mathbf{F}^T\mathbb{\Sigma}_\mathbf{C}^{-1}\delta \mathbf{F} \delta t \right],\ when\ \mathbb{dQ^*} = \frac{\exp(- |\rho| \mathcal{J}) \mathbb{dP}}{\int {\exp(- |\rho| \mathcal{J}) \mathbb{dP}} } \end{align} \cdots (31)\]4.3 Derivation of the sHJB Equation
Let’s introduce the assumption that the control dynamics are affine with respect to the input, as shown in equation (29).
\[\begin{align} \mathbb{P}^{\mathbf{Controlled}}: \mathbb{dx} & = \mathbf{f} \mathbb{(x)} \mathbb{d}t + \frac{1}{\sqrt{|\rho|}}\mathcal{B} \mathbb{(x)} \mathbb{dw}^{(0)}(t) \\ \mathbb{Q}^{\mathbf{Uncontrolled}}: \mathbb{dx} & = \mathbf{f} \mathbb{(x)} \mathbb{d}t + \mathcal{B} \mathbb{(x)} \biggl( \mathbf{u} \mathbb{d}t + \frac{1}{\sqrt{|\rho|}}\mathbb{dw}^{(1)}(t) \biggr) \end{align} \cdots (32)\]Applying the Legendre inequality to the free energy, we obtain the following:
\[\begin{align} \xi(\mathbb{x}) & = - \frac{1}{\rho} \log_e \mathbb{E_P} \biggl[ \exp \left( - |\rho| \mathcal{J}(\mathbb{x}) \biggr) \right] \\ & \leq \mathbb{E_P} \biggl[ \mathcal{J}(\mathbb{x}) + \frac{1}{2} \int_{t_i}^{t_N} \mathbf{u}^T\mathbf{u} \mathbb{d}t \biggr] \end{align} \cdots (33)\]Next, let’s introduce a new variable $\Phi$:
\[\mathbf{\Phi}(\mathbb{x}, t) = \mathbb{E_P}\left( \exp (\rho \mathcal{J}(\mathbb{x})) \right) \cdots (34)\]According to the Feynman-Kac Formula, this function follows the Kolmogorov Backward Equation, and the following equation holds:
\[- \partial_t \mathbf{\Phi} = \rho q_o \mathbf{\Phi} + \mathbf{f}^T(\nabla_\mathbb{x} \mathbf{\Phi}) + \frac{1}{2|\rho|} \mathrm{Tr} \biggl( (\nabla_{\mathbb{xx}} \mathbf{\Phi}) \mathcal{B} \mathcal{B}^T \biggr) \cdots (35)\]By applying a logarithmic transformation similar to the one used in the path integral framework, $\mathbf{\xi}(\mathbb{x}) = \frac{1}{\rho} \log \mathbf{\Phi}(\mathbb{x}, t)$, we derive the following equation. Depending on whether $\rho$ is positive or negative, the equation simplifies as follows:
\[- \partial_t \mathbf{\xi} = q_0 + (\nabla_\mathbb{x}\mathbf{\xi})^T \pm \frac{1}{2} (\nabla_\mathbb{x} \mathbf{\xi})^T \mathcal{B}\mathcal{B}^T(\nabla_\mathbb{x} \mathbf{\xi}) + \frac{1}{2|\rho|} \mathrm{Tr} \biggl( (\nabla_{\mathbb{xx}} \mathbf{\xi}) \mathcal{B} \mathcal{B}^T \biggr) \cdots (36)\]This equation is none other than the stochastic Hamilton-Jacobi-Bellman (sHJB) equation. Thus, we have derived the sHJB equation without introducing any explicit principle of optimality.
In conclusion, we have explored how the problem of complex optimal control can be mathematically linked to stochastic inference. In section 1, we examined classical deterministic optimal control problems and the Hamilton-Jacobi-Bellman (HJB) equation, utilizing dynamic programming for computation. In section 2, we introduced the formalization of stochastic optimal control problems and derived the sHJB equation. In section 3, we explored the derivation of the stochastic optimal control problem into the Kolmogorov backward equation and applied the Feynman-Kac formula for sampling-based computations. Finally, in section 4, we considered how the sHJB equation could be derived without the assumption of a principle of optimality, using the concept of free energy minimization from stochastic inference. This exploration captures the connection between recursive operations in differential equations, stochastic inference, and forward sampling.


Comments